这篇笔记涵盖了 C++ 数值类型和内存管理。
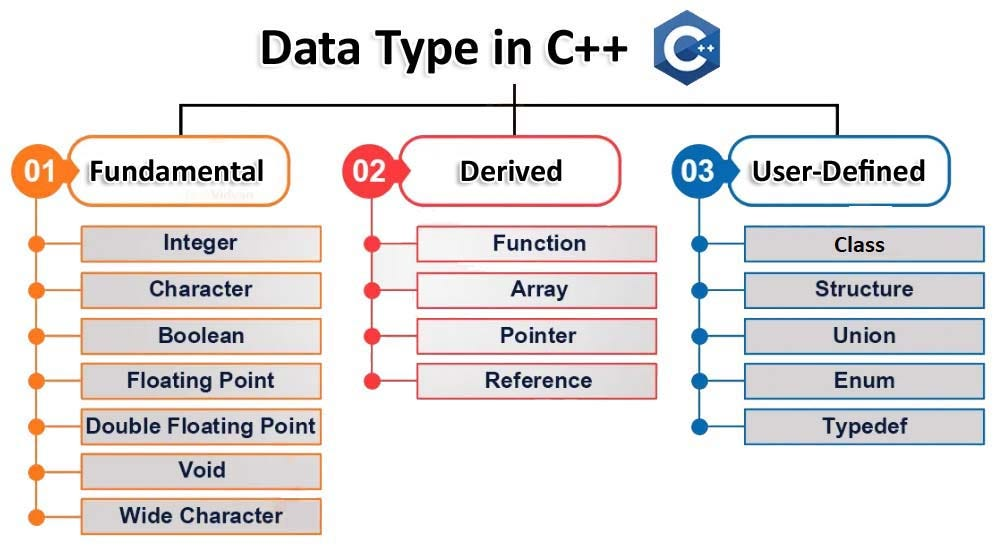
变量类型
可能涉及的变量类型如上所示。在本文中,一个 byte 指的是一个 8 位内存单元,即 1 byte = 8 bits。
简单变量
分类
- 整数类型:char (1 byte), short (2 bytes), int (4 bytes), long (4 bytes), long long (8 bytes)。
- 浮点类型:float (4 bytes), double (8 bytes), long double (12 或 16 bytes)。
布尔类型 (bool) 只有 true 和 false。C++ 将 0 解释为 false,将任何非零值解释为 true。
C++11 提供了固定宽度的整数类型:int16_t, int32_t, int64_t。它们的大小分别为 16 bits, 32 bits 和 64 bits(即 2/4/8 bytes)。
表示方式
整数表示:
- 如果整数是有符号的(signed),第 0 位始终表示符号(1 = 负,0 = 正);其余位表示数值大小。
- 如果整数是无符号的(unsigned),所有位都表示数值大小。
float (32 bits) 表示:
- 第 0 位 / 符号位 (1 bit):表示符号。1 = 负,0 = 正。
- 第 1–8 位 / 指数位 (8 bits):表示范围。
- 其余位 / 尾数位 (23 bits):表示精度。
例如:将 -15.5 表示为二进制位。
-
符号:负数,所以第一位是 1。
-
绝对值:15.5 = 15(int) + 0.5(decimal)
-
二进制转换:15 = (1111)_2, 0.5 = 1/2 = 2^(-1) = (0.1)_2
-
偏移量:15.5 = (1111.1)_2 = 1.1111 * 2^3, offset = 3+127 = 130 = (10000010)_2
-
尾数:1.1111 → .1111 → (填充至 23 bits) (11110000000000000000000)_2
现在组合所有二进制部分,-15.5 = (1 10000010 11110000000000000000000)_2
Double (64 bits) 表示:
- 计算步骤与 float 相同。
- 符号位:1 bit,指数位:11 bits,尾数位:52 bits。
类型转换
C++ 允许将一种类型的值赋给另一种类型的变量。
通常,赋值给范围更大的类型通常不会产生问题(例如 int 到 long)。然而,将较大的 long 转换为 float 可能会丢失精度,因为 float 只有大约六位有效数字。
将范围较大的值转换为较小的类型(当其超过该类型的范围时)通常只复制最右边的字节。
内存
内存是计算机存储程序指令、数据和状态的空间。计算机系统的主内存被组织为一个由 M 个连续的字节大小单元组成的数组,每个单元都有一个唯一的物理地址。
存储由一系列连续的单元组成;每个单元代表一个只有 0/1 状态的 bit。八个 bits 组成一个 byte。Byte 是内存寻址的最小单位;每个 byte 都有一个唯一的地址,因此计算机可以通过地址访问正确的 byte。
内存地址空间
所有可寻址内存地址的范围是计算机的可寻址内存范围。这组地址被称为内存地址空间。地址空间与系统是 32 位还是 64 位有关。32 位系统可以寻址 2^32 bytes = 4GB;如果计算机是 32 位的,安装超过 4GB 的 RAM 也无法使用多出的内存。
变量的本质
在 C/C++ 中,定义一个变量在语法上很简单。
C++int a = 999;
char c = 'c';
当我们声明一个变量时,我们请求一部分内存来存储它。例如,一个 int 占用 4 bytes,所以我们需要 4 bytes。数字以补码形式存储;999 的补码是 0000 0011 1110 0111——每 4 bits 存储在一个 byte 中。
Byte 可以按两种顺序存储:要么是 0000 0011 1110 0111,要么是反向存储。将高位字节存储在低地址是 big endian(大端序);反之则是 little endian(小端序)。Big endian 符合人类的阅读习惯。这种顺序被称为字节序(byte order)。
我们可以通过 C++ 代码确定系统的字节序。例如:
C++int main() {
int num = 1;
char* ptr = reinterpret_cast<char*>(&num);
if(*ptr==1) {
cout << "Little-endian" << endl;
} else {
cout << "Big-endian" << endl;
}
return 0;
}
我们可以这样做是因为整数 num 被初始化为 1 (0x0000 0001),通过将其指针从 int* 转换为 char*,我们可以访问第一个 byte。如果系统是 little endian,第一个 byte 是 1;否则是 0。通过检查第一个 byte,我们就能知道字节序。
通常,PC 和 Mac 使用 little endian;网络传输(特别是 TCP/IP)使用 big endian。Linux 则视情况而定。
内存区域
当程序运行时,代码、数据等被存储在不同的内存区域。这些区域在逻辑上分为:代码段(code section)、全局/静态存储区(global/static storage)、栈(stack)、堆(heap)和常量区(constant section)。
代码段 (Code Section)
也称为 .text 段。代码段保存程序的二进制代码。它是只读的,以防止在运行时被意外修改。它还可能包含只读常量,如字符串字面量。
全局 / 静态存储区 (Global / Static Storage)
存储全局变量和静态变量。该区域的内存在几乎整个程序生命周期内都持续存在。例如:
C++int globalVar = 0;
void function() {
static int staticVar = 0;
staticVar ++;
cout << staticVar << endl;
}
int main() {
function();
function();
return 0;
}
在这里,globalVar 是全局变量,staticVar 是静态变量;两者都驻留在全局/静态存储区。
static 关键字
关于 static 关键字的几点说明:
- 在函数内部:例如,void function() 内部的 static int——在函数内部声明的静态变量在整个程序生命周期内保留其值。即使在函数返回后,静态变量的值也不会丢失;在下次调用时,它仍然具有之前的值。在上面的程序中,调用 function() 两次分别输出 0 和 1,尽管非静态局部变量在第一次调用后本应丢失其值。
- 在类中(修饰变量):在类中声明的静态成员变量是共享的;该类的所有对象都访问同一个变量。静态成员在类中声明,但必须在类外定义和初始化。这使得它们适用于单例模式(singleton pattern),例如:请注意,在这个类中,health 被标记为 static int,因此我们可以在 main() 中修改/使用 health 而无需创建 GameManager 实例。在这里,单例是通过在 getInstance() 中创建一个静态 GameManager 实例来实现的。因为变量在函数内部是静态的,所以它在后续调用中不会被重新创建。
C++#include <iostream>
class GameManager {
public:
static int health;
static GameManager& getInstance() {
static GameManager instance;
return instance;
}
GameManager(const GameManager&) = delete;
GameManager& operator = (const GameManager&) = delete;
void show() {
std::cout << "This is the GameManager singleton instance." << std::endl;
}
static void showHealth() {
std::cout << "Health:" << health << std::endl;
}
private:
GameManager() {}
};
int GameManager::health = 0;
int main() {
GameManager::health = 80;
GameManager::getInstance().show();
GameManager::showHealth();
return 0;
}
- 在类中(修饰方法):静态成员函数可以在不实例化对象的情况下调用。静态成员函数只能访问静态成员,不能访问非静态成员。在上面的代码中,注意(非静态)函数 show() 和静态函数 showHealth() 之间的区别。
无论哪种情况,静态变量都存储在全局/静态存储区。请记住这一点。
栈 (Stack)
栈存储局部变量、函数参数以及函数调用时的返回地址。
当函数返回时,分配给它的栈空间会自动释放。例如:
C++#include <iostream>
void function(int a, int b) {
int s = a + b;
std::cout << s << std::endl;
}
int main() {
function(3, 4);
return 0;
}
在这里,s 是局部变量,a 和 b 是函数参数,因此它们的数据都在栈上。当 function() 返回时,相应的栈空间会被回收。
堆 (Heap)
堆用于动态内存分配。在 C++ 中使用 new(或在 C 中使用 malloc)分配的内存驻留在堆中。我们必须手动释放这些内存,否则会有内存泄漏的风险。例如:
C++#include <iostream>
int main () {
int* array = new int[10];
delete[] array;
return 1;
}
常量区 (Constant Section)
字符串字面量和其他编译时常量驻留在常量存储区,该区域通常是只读的。
内存管理
动态内存分配
当 C/C++ 程序在运行时需要额外的虚拟内存时,我们使用动态内存分配器来请求新的内存块。
动态内存分配器维护进程的虚拟内存区域——堆。分配器将堆视为一组大小不一的块的集合;每个块都是一块连续的虚拟内存,要么是已分配的,要么是空闲的。
已分配的块正由应用程序使用;空闲块是可用的。当不再需要某个块时,我们必须释放它,以便将来的请求可以使用它。释放可以是:
- 显式 (Explicit):例如 C 中的 free,C++ 中的 delete
- 隐式 (Implicit):例如 Java、C# 中的垃圾回收器 (Garbage Collector)
当程序需要使用一个块时,它会要求动态内存分配器分配一个。分配始终是显式的,例如 C 中的 malloc,C++ 中的 new。
内存碎片
有时空闲内存的总量可以满足 malloc/new 请求,但由于空闲块在物理上被分割成许多散落在堆中的碎片(或被已分配的块隔开),new 无法获得足够大的连续块。这就是内存碎片。
这也被称为外部碎片。内部碎片也可能发生:已分配的块大于其有效载荷(payload),因为分配器可能为了满足最小块大小要求而分配了一个更大的块。
空闲链表 (Free Lists)
空闲链表是分配器用于查找和使用空闲块的数据结构。有许多实现方法。
隐式空闲链表 (Implicit Free List)
一个简单的块结构可能是:
- 头部 (Header):块大小(前 29 bits)和分配状态(最后 3 bits,001 = 已分配,000 = 空闲)。
- 有效载荷 (Payload):malloc/new 请求的有效载荷。
- 填充 (Padding,可选):可能用于满足对齐或其他要求。
空闲块通过头部的大小字段隐式链接(从堆起始处遍历,查找分配位为 0 的块,比较大小)。
优点:概念和实现简单。缺点:速度慢。
显式空闲链表 (Explicit Free List)
在显式空闲链表中,每个空闲块在头部之后都有 pred 和 succ 指针,指向前一个和后一个空闲块。已分配的块与隐式情况相同。分配时间从与总块数成线性关系变为与空闲块数成线性关系。释放时间可以是 O(N) 或 O(1),取决于我们是按 LIFO 顺序还是按地址顺序存储链表。
显式链表优化了首次适配 (first-fit) 时间,但需要更大的最小块大小(空闲块必须存储头部和指针),这可能会增加碎片。
分离空闲链表 (Segregated Free Lists)
与其维护一个空闲链表,不如维护多个大小类 (size classes),并在对应大小类的链表中进行搜索。
参考资料
- 编程指北公众号: https://csguide.cn/cpp/memory/what_is_memory.html
- C++ Primer Plus.