データ構造 #1 木構造
- Lingheng Tao
- 2024年10月21日
- 読了時間 3 分
Algorithms & Data Structure Content List
#ComputerScience#SWE
このノートはデータ構造(木)に関するものです。ノートでは厳密で退屈な数学的言語を避け、直感的な理解を最優先とします。
基本概念
一般に、木は自由木と有根木に分かれる。自由木は連結で閉路のない無向グラフであり、有根木は連結で閉路のない無向グラフであるが、他の頂点と異なる1つの頂点が存在し、それを木の根(root)と呼ぶ。
以下のノートでは、特に断らない限り有根木を扱う。
有根木のデータ構造
有根木では、頂点はノード(node)とも呼ばれる。木には枝があり、ノード x は別のノード y の子ノード(children)となり得る。この場合、ノード y はノード x の親ノード(parent)である。木では、ノードは複数の子を持ち得るが、親は1つしか持てない。同じ親を共有する2つのノードは兄弟ノード(sibling)と呼ばれる。
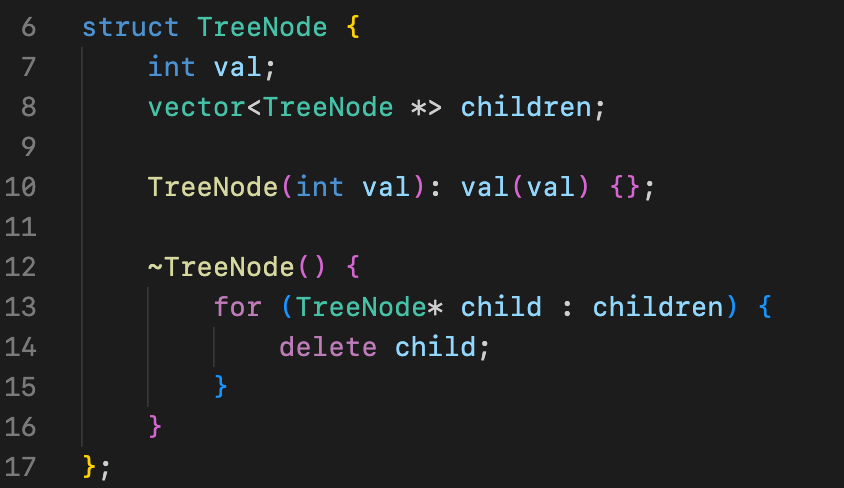
これらの概念に基づき、TreeNode データ構造を簡単に書ける。ここでは struct を直接使用する。
このとき、TreeNode *head で有根木の根ノードへのポインタを表せる。連結性により、根ノードがその木を直接表す。
二分木のデータ構造
特に、二分木(Binary Tree)は有限のノード集合上で定義される構造で、ノードを含まないか、または3つの互いに素なノード集合を含む:1つの根ノード、1つの左部分木(同様に二分木)、1つの右部分木(同様に二分木)。ノードを含まない二分木は空木である。ノードが左部分木も右部分木も持たない(または左右部分木がともに空木)場合、そのノードを葉ノード(leaf)と呼ぶ。
TreeNode データ構造を簡単に修正すれば、二分木ノード専用にできる。
特に、完全二分木(Complete Binary Tree)とは、各層のノードが可能な限り満たされ、最後の層(葉)を除くすべての層でノード数が最大に達し、最後の層のノードが満たされていない場合、それらのノードは左から右に連続して並び、右に空きがあり得るが、途中に空きはない木である。
完全二分木には以下の性質がある:
- 深さ d の完全二分木の最大ノード数は 2^d - 1。
- ノード数 n の木のうち、完全二分木は高さが最小(木の高さとは根から任意の葉ノードまでの最長経路の長さ)。
満二分木(Full Binary Tree)とは、各ノードが0個または2個の子を持ち、すべての葉が同じ層にある木。満二分木は完全二分木の特殊な場合である。
基本アルゴリズム
有根木の走査
有根木に関するすべてのアルゴリズムの中で、走査(traverse)は比較的簡単で基本的なアルゴリズムである。木の性質を利用し、再帰やスタック・キューで直感的なアルゴリズムを書けることが多い。
二分木を例に、前順(preorder)、層順(level order)、中順(in order)、後順(post order)の4つの走査順序を紹介する。走査結果を vector に格納して出力すると仮定する。
前順走査
前順走査の順序は根 → 左 → 右。したがって非常に簡単。
注:再帰の過程では、既に書いた result 配列を参照渡しし、vector::insert() の使用を避ける。追加のコピーと効率問題を招く可能性がある。
中順走査
中順走査の順序は左 → 根 → 右。上記の再帰的方法とほぼ同じ。
後順走査
後順走査の順序は左 → 右 → 根。上記の再帰的方法とほぼ同じ。
層順走査
層順走査では層ごとに訪問し、各層は左から右。ここでは再帰を使わず、キューを使用する。キューは先入れ先出しなので、各層で左の木を先にキューに入れ、右の木を後にキューに入れ、順番にキューから pop して走査する。
子の数に制限のない有根木
各ノードの子ノード数が有限の定数なら、最初の方法で木を記録できる。子の数が任意の木を表す巧妙な方法もある。O(n) の記憶領域のみで、左子右兄弟表現(left child, right sibling)と呼ばれる。